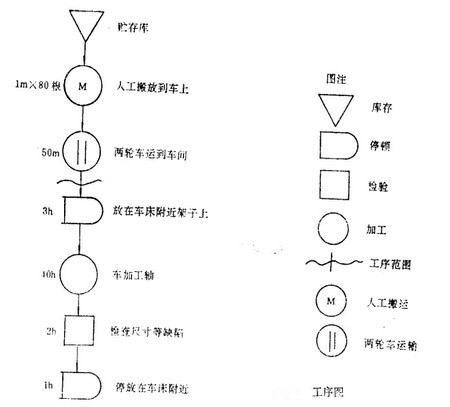
2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
凌晨两点,我被一通报警电话惊醒。一位用户抱怨我们的智能客服代理“小易”突然失忆——它在上一轮对话中刚被告知用户名叫“老王”,却在下一轮问道:“请问您叫什么名字?”除此之外别无他因:记忆消失了。我打开数据库,手动梳理了数千条向量记录,试图找到那次对话的日志,并比对嵌入相似度。我一直工作到天亮,眼睛几乎充血,才终于定位到问题所在:一个并发时序问题导致更新操作用旧版本覆盖了新写入的记忆。那一刻我心想:这种烂事绝不会再让人工验证第二次。
剖析问题
如果你曾为智能体构建过记忆模块,你就完全明白我所说的那种痛苦。如今,智能体的记忆存储通常由向量数据库支撑——对话历史、用户偏好、事实信息都被编码成向量,写入 Chroma / Qdrant / Milvus,随后通过相似度搜索检索相关记忆。听起来简单,但一致性验证却如同地狱:
-
更新并非精确替换:插入更新后的记忆并不是简单的
UPDATE SET vector=? WHERE id=?。相反,你需要插入一个新向量,并将旧记录标记为无效。如果在这两个步骤之间发生检索,用户可能会获取到过时的记忆。 - 近似匹配的“不确定性”:由于模型精度和浮点误差,同一段文本两次嵌入后,其余弦相似度可能并不恰好等于 1.0。因此在测试中,你应该断言其等于 1.0,还是仅大于 0.99?什么阈值才合适?人工验证全靠直觉。
-
元数据与向量的解耦:你无法通过视觉判断向量是否正确。你必须依赖辅助元数据字段(如
user_id、session_id、ts)来定位记录。在人工验证期间,你必须同时打开三个窗口:日志、数据库查询以及计算向量距离的脚本。
标准的单元测试方法根本无法应对这种情况——因为嵌入过程通常依赖于外部模型服务,单元测试要么对其进行模拟,要么运行速度慢得令人难以忍受。另一方面,集成测试往往只检查“能否返回结果”,而不关心“返回的结果是否精确正确”。因此,当时我们的测试流程是在发布前人工运行 20 次对话,然后查询数据库——这一过程的漏测率极高,那个并发 bug 正是由此溜进了生产环境。
设计解决方案
在那次痛苦的经历之后,我决定构建一个确定性的、自动化的一致性验证流水线。具体选择如下:
- 测试框架:Pytest。其丰富的生态系统、固件(fixtures)和参数化功能使得管理测试资源和多种场景变得容易。我跳过了 unittest,因为它过于冗长;也跳过了 Robot Framework,因为它过于笨重。
- 向量数据库:继续使用 Chroma(已在生产环境中使用)。但在测试时,切换到隔离的测试集合,使用固件在每次测试前创建并在测试后销毁它。
-
嵌入方法:硬编码一个伪造的嵌入函数,返回可控的、固定长度的向量。为什么不用随机向量进行模拟?因为我需要可精确计算的距离。我可以为两段文本构造向量,使它们的距离恰好
免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。